豆瓣热映电影网页生成器
爱盼项目上显示了豆瓣热映和电视剧等信息,自己也想要一个这样的页面,不会写怎么办,呼叫deepseek生成一个。
生成的代码
脚本需要的Python库
- requests
- beautifulsoup4
pip install requests beautifulsoup4
运行脚本
它会:
- 从豆瓣电影获取当前热映电影信息;
- 解析电影标题、评分、导演、演员、海报等信息;
- 生成一个美观的HTML页面展示这些电影;
- 将HTML保存为”douban_movies.html”文件。
添加豆瓣链接和评分星级
在 generate_html() 函数前添加 generate_star_rating() 辅助函数:
放在 generate_html() 函数定义之前,作为独立的辅助函数。修改 generate_html() 函数中的电影卡片HTML模板:
替换原来的 movie_html 部分。
修改部分完整代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53def generate_star_rating(score):
"""生成星级评分"""
try:
score = float(score)
full_stars = int(score // 2)
half_star = 1 if score % 2 >= 1 else 0
empty_stars = 5 - full_stars - half_star
return '⭐' * full_stars + '½' * half_star + '☆' * empty_stars
except:
return ''
def generate_html(movies):
"""
生成展示热映电影的HTML页面
"""
html_template = """
<!DOCTYPE html>
<html lang="zh-CN">
<!-- 之前的HTML模板保持不变 -->
</html>
"""
from datetime import datetime
update_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
movies_html = ""
for movie in movies:
movie_html = f"""
<div class="movie-card">
<a href="https://movie.douban.com/subject/{movie.get('id', '')}/" target="_blank">
<img class="movie-poster" src="{movie.get('poster', '')}" alt="{movie.get('title', '')}">
</a>
<div class="movie-info">
<div class="movie-title">
<a href="https://movie.douban.com/subject/{movie.get('id', '')}/" target="_blank">
{movie.get('title', '')}
</a>
</div>
<div class="movie-meta">导演: {movie.get('director', '未知')}</div>
<div class="movie-meta">主演: {movie.get('actors', '未知')}</div>
<div class="movie-meta">地区: {movie.get('region', '未知')}</div>
<div class="movie-meta">片长: {movie.get('duration', '未知')}</div>
<div class="movie-rating">
评分: {movie.get('score', movie.get('star_rating', '暂无评分'))}
{generate_star_rating(movie.get('score', 0))}
</div>
</div>
</div>
"""
movies_html += movie_html
full_html = html_template.format(movies_html=movies_html, update_time=update_time)
return full_html
注意事项
- 豆瓣可能有反爬虫机制,图片会显示不了,可以尝试更换User-Agent或添加延迟
添加Referrer Policy(简单方案)
在HTML的中添加:<meta name="referrer" content="no-referrer"> - 电影信息的HTML结构可能会变化,如果解析失败可能需要调整代码;
- 生成的HTML页面是静态的,不会自动更新。
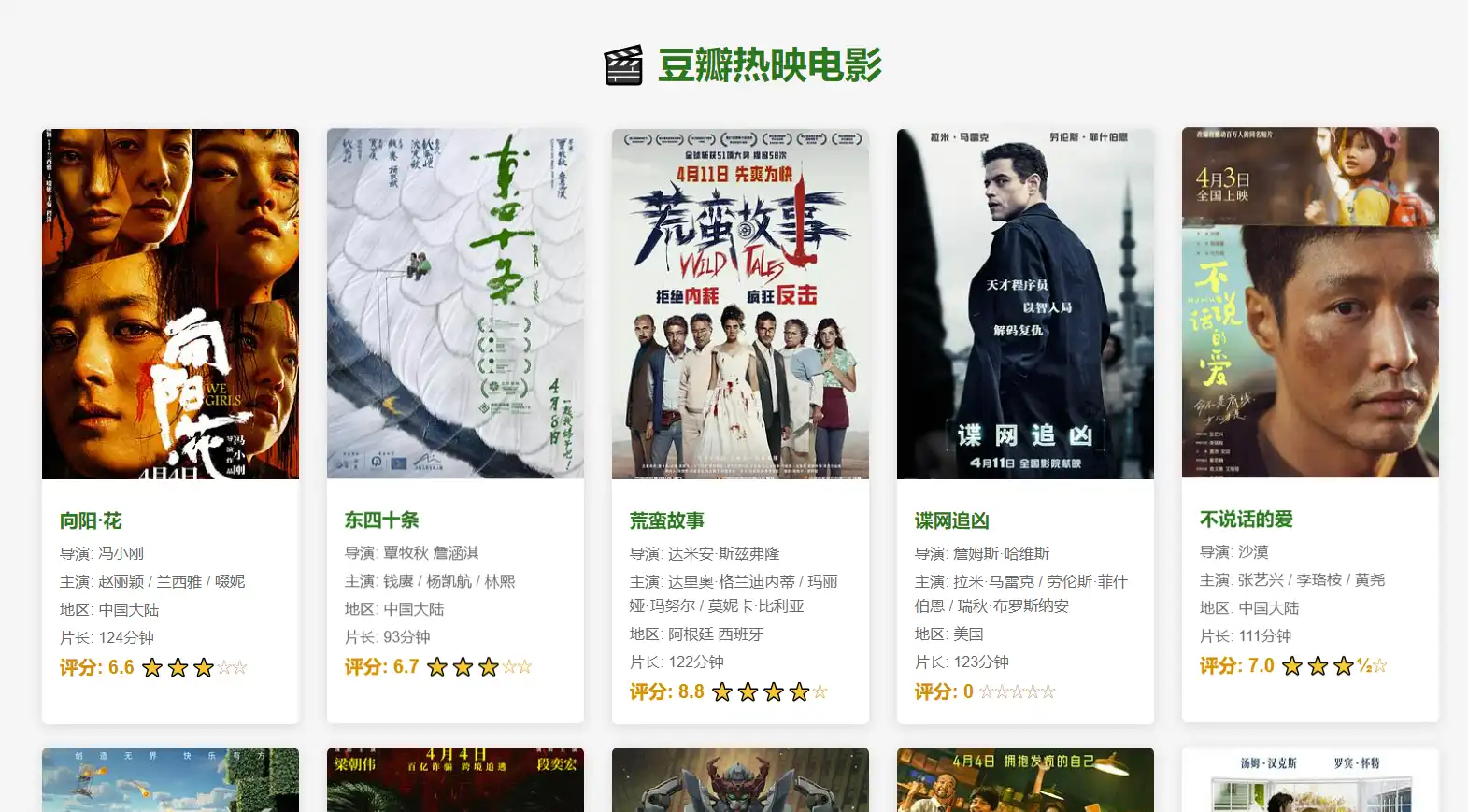
生成代码很容易,但也要一步一步改进才能得到想要的结果,比自己抠代码要简单多了。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 折腾日记!
评论




